|
guida modificata: Ottobre 2013
NOTA PER TUTTI: In questo momento
Cuneiform è il miglior programma gratuito/open source per il
riconoscimento ottico dei caratteri (ma non lo conoscevo
quando scrissi questa guida).
Su Programmifree esiste anche una
guida per Cuneiform;
l'avevo scritta per digitalizzare i testi con lo scanner, ma la si
può utilizzare anche per convertire i PDF in Word (o in qualunque
formato di testo), semplicemente salvando le pagine del PDF in immagini
(PNG, BMP, ecc.) e poi procedendo da lì.
Per riconoscimento ottico dei
caratteri (in breve OCR) si intende la capacità del computer di
riconoscere il testo presente in un'immagine, in genere acquisita
attraverso uno scanner, ma anche -per esempio- da un documento PDF.
Una volta che il computer avrà
riconosciuto quell'immagine come documento di testo, sarà possibile
utilizzare tutte le normali funzioni che si usano su un normale testo,
come ricerca e sostituzione, controllo ortografico, cambiare carattere e
impaginazione, ecc.
Purtroppo i programmi di OCR sono in
genere costosi (Omnipage e Fine Reader i più famosi), ma anche dotati di
caratteristiche che non si trovano nei corrispondenti programmi
gratuiti, a partire dalla capacità di riconoscere automaticamente il
layout di una pagina e di riprodurlo tale e quale, oppure di caricare e
convertire direttamente in .doc (o altro formato testuale) i documenti
PDF.
Per chi non vuole spendere, comunque, esistono oggi dei programmi
gratuiti abbastanza buoni anche per la lingua italiana, come
FreeOCR/Tesseract. Con questo programma è anche possibile convertire i
documenti PDF, ma a prezzo di un paio di passaggi in più.
Ecco dunque una guida per
FreeOCR/Tesseract comprensibile a tutti.
-
Scaricate e installate
FreeOCR (esattamente dove
c'è scritto download)
-
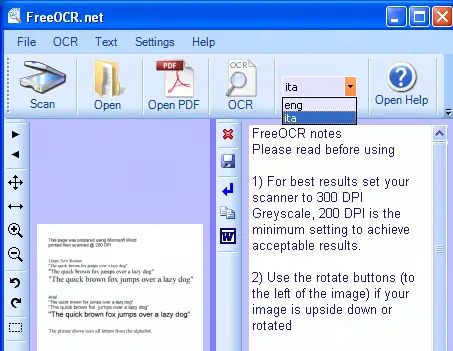
Avviate
FreeOCR e impostate
a lingua italiana, come nell'immagine qui sotto:
-
Acquisite il testo. Se
avete uno scanner, impostatelo a 300dpi. In genere impostando una
risoluzione superiore o inferiore si ottengono risultati peggiori (a
meno di caratteri microscopici, nel qual caso si può salire a 600 dpi).
Se avete un documento PDF, potete direttamente cliccare su
OpenPDF.
-
Adesso è molto importante
delimitare il testo con il mouse, tracciando un rettangolo intorno alla
parte del testo da convertire, soprattutto se i bordi della pagina
digitalizzata sono un po' scuri (se non lo fate, il testo si potrebbe
riempire di caratteri strani).

-
Cliccate
 e finalmente potrete avere in italiano il vostro documento.
e finalmente potrete avere in italiano il vostro documento.
Pur non essendo
paragonabile ai programmi del genere a pagamento, FreeOCR svolge lo
stesso un lavoro abbastanza buono, e se imparete bene ad usarlo (non che
ci voglia molto...), otterrete dei risultati soddisfacenti.
|




